
ТЕХНИКА ОПТИМИЗАЦИИ
В прошлом году я просил у Санта Клауса подарить мне суперкомпьютер Cray XPM, но, как обычно, он не принес ничего. И если вы не будете использовать компьютер с фемисекундным циклом выполнения команд и террабайтами оперативной памяти, нам обоим придется примириться с ПК.
Следовательно, мы должны делать наши программы видеоигр настолько быстрыми, настолько возможно. Для этого мы должны постараться выжать из ПК каждую унцию его мощности. В данной главе мы охватим следующие темы, связанные с приемами оптимизации:
§ Передача параметров;
§ Глобальные переменные;
§ Указатель и ценность псевдоимени;
§ Использование регистров;
§ Оптимизация компилятора;
§ Развертка циклов;
§ Бинарное умножение;
§ Таблицы поиска;
§ Математика с фиксированной точкой;
§ Встроенный ассемблер;
§ Предмет изучения;
§ Оптимизация построения пикселя;
§ Оптимизация изображения пикселя.
Введение
Прежде чем углубиться в изучение приемов оптимизации видеоигр для ПК, я хочу дать вам несколько советов. Когда вы оптимизируете свои программы, не пытайтесь разом провести полную оптимизацию. В первую очередь обратите внимание на те части, время выполнения которых критично и где встречается наибольшее количество циклов. Возьмите эти функции и работайте с ними до тех пор, пока их быстродействие не начнет вас удовлетворять.
Попытка оптимизации всей игры за раз, как правило, приводит к полному беспорядку, и вы никогда не сможете ни отладить программу, ни добавить что-либо в игру. Оптимизация должна быть взвешенной с точки зрения наличия других факторов. Если оптимизация функции принесет ей лишние три процента быстродействия, но при этом сделает ее вдвое запутаннее, то стоит попробовать найти другое место для оптимизации.
Не пытайтесь свалить все операторы, в кучу и свести десяток строк программы к одной. Ненавижу смотреть на выражения типа
* (х+(у++) >=*(& (х++)>>2)+(char far *)y;
Получили представление? Такая запись не только выглядит коряво с точки зрения Си, но и Codeview вряд ли поможет вам в отладке строк, подобных этой.
Поскольку мы разрабатываем видеоигры, я могу гарантировать, что 90% времени будет затрачено не на осуществление игровой логики, а на различные графические преобразования. Поэтому нужно сделать все функции рисования настолько быстрыми, насколько это возможно, а строки, управляющие игрой, имеет смысл оставить простыми и понятными. Функция, рисующая на экране точку, может представлять собой «черный ящик», а игровая программа в целом — нет. Оставляйте ее удобочитаемой. С помощью приемов оптимизации, которые мы изучим в этой главе, быстродействие практически любой функции может быть увеличено от 2 до 10 раз. Не говоря о том, что вы получите замечательные результаты, еще и произведете впечатление на друзей.
Передача параметров
Из второй главы «Основы языка ассемблерам (да и из собственного опыта) вы должны помнить, что передача параметров функциям не является свободной в полном смысле слова. Параметры должны быть помещены в стек, сделаны доступными через использование указателя базы и, наконец, взяты со стека. Если вам нужна функция, которая складывает 8 чисел, передаваемых как параметры, то потребовалось бы написать что-нибудь вроде этого:
int Add_Em_All(int nl,int n2,int n3,int n4,
int n5,int n6,int n7,int n8)
{
return (n1+n2+n3+n4+n5+n6+n7+n8);
}
(Конечно, это не является реальной функцией. Я привел ее только в качестве наглядного примера.) После компиляции этой функции ее тело будет выглядеть примерно так:
clc
mov ax,00h
adc ax,n1
adc ax,n2
adc ax,n3
adc ax,n4
adc ax,n5
adc ax,n6
adc ax,n7
adc ax,n8
Конечно, в самом начале приведенного фрагмента необходимо создать фрейм стека и уничтожить его в конце. Однако суть в том, что на восемь выталкиваний и извлечений параметров уходит немало времени. Если вы посмотрите на скорость выполнения команд PUSH и POP, то обнаружите, чти они отнимают в три раза больше тактов процессора, чем ADC. Как видите, в данном случае передача параметров отнимает больше времени, чем выполнение самой функции. Это показывает нам, что мы должны стараться передавать только те переменные, которые действительно необходимы.
Также никогда не передавайте структуры как значения. Если вы определите структуру, написав что-либо похожее на это:
typedef struct point_typ
{
int x[10],y[10],z[10];
}point,point_ptr;
сделаете вызов
Display(point point_1);
то в стек будет помещена целая структура! Это очень плохо. Чтобы избежать подобного, при передаче структур всегда применяйте ссылки на них, а «передачу значением» используйте только для целых и прочих стандартных типов данных Си.
Может быть, вы спросите: «Почему не использовать глобальные переменные вместо параметров?» Рассмотрим эту идею более внимательно.
Глобальные переменные
Мы пишем видеоигры, правила которых иногда должны изменяться. Всякий, кто где-нибудь учился, знает, что глобальных переменных стоит по возможности избегать. Конечно, всякое бывает, но лучше, когда их очень мало, и прекрасно, когда они вообще отсутствуют. Здесь приведена точка зрения одного крутого знатока в программировании игр; «Используйте глобальные переменные всегда, когда они помогают в увеличении быстродействия, но при этом сохраняйте чувство меры». К примеру, у нас есть набор функций, которые рисуют точки, изображают линии и окружности.
Эти функции требуют передачи им различного количества параметров: для построения точки нужно знать две координаты, а для рисования линии — целых четыре. Что же касается цвета, то он, вероятно может быть одним и тем же как для линий, так и для окружностей. Почему же не сделать, чтобы каждая функция рисовала текущим глобальным цветом? С этой целью можно задать переменную и назвать ее, например, draw_color. Если вы измените текущий цвет и сделаете сотню вызовов функции, то при этом изменить цвет достаточно будет только один раз. В результате вы сумеете избежать порядка двухсот операций обмена со стеком.
Но учтите, что применение глобальных переменных может оказаться немного похожим на употребление наркотика: чем больше его принимаешь, тем больше он нужен. Хороший программист всегда может сбалансировать использование глобальных переменных и увеличить с их помощью быстродействие программы на 5, а то и 10 процентов.
Указатели и использование псевдоимен
Эту тему условно можно назвать тактическим приемом, которым пользуются некоторые программисты, в то время как многие о нем даже и не подозревают. Например, у вас есть фрагмент такой программы:
for(t == y->stars[index].left;
t < stars[index].left + 100; t++)
{
position = point->x + point->y -point->z;
pitch = point->x * point->y * point->z;
roll-= point->ang + sin(t) * point->ang;
}
Этот фрагмент хоть и выглядит достаточно компактным, но, тем не менее, и к нему может быть применен способ оптимизации, связанный с использованием псевдоимен. Вы видите, что в этом примере присутствует несколько команд, ссылающихся на указатель. Тактика, которой мы здесь воспользуемся, заключается в замене всех указателей, встречающихся более двух раз, простыми переменными. Вышеуказанная функция в результате может быть переписана так;
t1=y->stars[index].left;
x=point->x;
y=point->y;
z=point->z;
ang=point->ang;
for(t=t1;t<t1+100;t++)
{
position=x+y+z;
pitch=x*y*z;
roll=ang+sin(t)*ang;
}
Несмотря на то, что новая версия длиннее, она выполняется быстрее, так как содержит только пять ссылок вместо 800. Конечно, доступ к переменным х, у и z отнимает некоторое время, но порядок его величины меньше, чем ссылки на структуры и указатели. И этим нужно воспользоваться.
Использование регистров
В конечном счете, все программы, которые мы пишем на Си, будут переведены в последовательность машинных команд. После этого превращения некоторые из регистров общего назначения окажутся занятыми выполнением задачи, определяемой программой. Однако, мы не можем быть уверенными, что регистры будут использоваться вместо медленной стековой памяти. Чтобы быть уверенным, что функции используют регистры для переменной индекса (или какой-нибудь другой), давайте попробуем заставить компилятор по мере возможности делать это. Необходимо всегда помнить, что доступ к регистрам процессора во много раз быстрее, чем к оперативной памяти. Это происходит потому, что регистры находятся внутри ЦПУ, а память - нет. Мы можем использовать ключевое слово register, чтобы скомандовать компилятору использовать регистр. Как пример, напишем функцию, которая делает перестановку без регистров.
void Swap(int..num l,num 2)
{
int temp;
temp=num_1;
num_l=num_2; num_2=temp;
}
А теперь перепишем ее, используя регистр как временную переменную.
Swap(int num_1,num_2)
{
register int temp;
temp=num_1;
num_1=num_2;
num_2=temp;
}
Если компилятор может, то он будет использовать регистр в качестве регистровой переменной и программа увеличит скорость выполнения на 10-15 процентов. В связи с использованием ключевого слова register нужно учитывать два момента:
§ Компилятор не создает регистры, он использует стандартные регистры ЦПУ;
§ Иногда форсирование компилятора для использования регистров делает программу медленнее. Будьте осторожны. Обычно не стоит применять переменные типа register в маленьких функциях.
Теперь поговорим об основных приемах оптимизации компилятора.
Оптимизация компилятора
Фирма Microsoft уверяет, что ее компилятор является оптимизирующим. Это предельно правдивое высказывание. Несмотря на то, что оптимизатор иногда в состоянии сделать вашу программу медленнее или даже привнести ошибки, он проводит классическую оптимизацию (с точки зрения ученых-компьютерщиков). Однако мы, как создатели игр, не можем доверять автоматической оптимизации. Следовательно, мы никогда не будем использовать никакие опции оптимизатора (хорошо, может быть только некоторые из них). Стоит попробовать поиграть с ними только когда ваша видеоигра уже полностью готова и свободна от ошибок. Но ни в коем случае не рассчитывайте на оптимизацию во время разработки программы. Это не панацея. Единственное, что может принести реальную пользу, так это опция отключения контроля переполнения стека.
Обычно компилятор в начале любой процедуры вставляет небольшие фрагменты кода, называемые прологом, которые служат для проверки достаточности стекового пространства для размещения локальных переменных. Но если установить размер стека в несколько килобайт, то у вас никогда не будет проблем. Поэтому вы можете выключить контроль переполнения стека, что немного сократит время обращения к функции (для этого можно использовать директиву компилятора -GS).
Я считаю, что оптимизатор на самом деле может доставить хлопот больше, нежели разрешить проблем. Вскоре я специально напишу эффективную программу, чтобы доверить ее оптимизатору и посмотреть, что из этого получится. Иногда оптимизатор может без зазрения совести внести в вашу программу пару-тройку ошибок, и это является еще одной причиной, почему им не стоит пользоваться слишком активно. (Я уже задокументировал дюжину ошибок в новом компиляторе Microsoft — Visual C/C++ 1.5, так что это высказывание имеет под собой серьезное обоснование. Обычно я до сих пор использую C/C++ 7.0, находя его более надежным.)
Развертка циклов
Это очень старо. В далеком прошлом, в конце 70-х годов, когда Apple безраздельно правил миром ПК, королем среди процессоров считался процессор 6502.
Люди всегда находили интересные пути, чтобы заставить его работать быстрее. Один из трюков, который был найден, называется разверткой циклов. Это технический прием, где программист на самом деле отменяет структуру цикла вручную, разбивая саму задачу цикла. Структура цикла сама по себе имеет небольшой заголовок и мы можем использовать это в наших целях. К примеру, мы хотели бы инициализировать поле men в 10000 структур. Можно было бы поступить так:
for (index=0;index<10000;index++)
{
player[index].men=3;
}
и это будет прекрасно работать. Однако переменная index инкрементируется и сравнивается 10000 раз. Поскольку цикл повторяется 10000 раз, то это означает, что будет 10000 переходов типа NEAR. Мы можем развернуть цикл и получить небольшой выигрыш в скорости его выполнения. Вот что мы могли бы сделать:
for(index=0;index<1000;index+=10)
{
player[index].men=З;
player[index+1].men=3;
player[index+2].men=3;
player [index+3].men=3;
player[index+4].men=3;
player [index+5].men=3;
player [index+6].men=3;
player[index+7].men=3;
player [index+8].men=3;
player[index+9].men=3;
}
Теперь цикл выполняется только 1000 раз. Следовательно, index изменяется и сравнивается только 1000 раз, и при этом выполняется только 1000 переходов типа NEAR.
Этот пример написан мною еще и для того, чтобы показать вам, что развертка цикла может иметь и отрицательные стороны. Посмотрите внимательно на новую программу. Здесь к каждому индексу в каждой последующей операции присваивания добавляется смещение, и время, которое уйдет на это, может свести на нет выгоду от разворачивания циклов. Однако, чтобы исправить это, мы можем применить маленькую хитрость. Введем для индексирования структуры вторичную переменную new_index, которую будем увеличивать после каждого присваивания. Это приведет к увеличению скорости. Взгляните:
new_index=0;
for(index=0;index<1000;index+=10)
{
player[new_index++].men=3;
player[new_index++].men=3;
player[new_index++].men=3;
player[new_index++].men=3;
player[new_index++].men=3;
player[new_index++].men=3;
player[new_index++].men=3;
player[new_index++].men=3;
player[new_index++].men=3;
player[new_index++].men=3;
}
Новая программа работает быстрее, чем старая. Неплохо? Развертка циклов настолько эффективна, что у вас может возникнуть желание постоянно прибегать к этой уловке. Однако и здесь нужно знать меру. Дело в том, что машинные команды кэшируются внутри современных CPU, и слишком «массированное» разворачивание циклов может привести к проблемам переполнения кэша. Но если вы пользуетесь этим бережно (то есть ограничиваетесь тремя-восемью итерациями), то должны получить хорошие результаты.
Теперь поговорим о другом старом трюке - использовании операций сдвига для перемножения чисел.
Бинарное умножение
Впервые мы столкнулись с этим трюком в пятой главе, «Секреты VGA-карт». На ПК (да и вообще почти на любом компьютере на этой планете) система двоичных чисел используется для представления чисел в компьютере (хотя, я слышал и о «троичных» компьютерах). Поскольку разряды двоичных чисел являются степенью двух и каждое число помещается в слове как набор двоичных цифр, сдвиг слова влево или вправо смещает каждый его разряд на соседнее место. Эти операции автоматически удваивают число или делят его на два, соответственно. Взгляните на рисунок 18.1, чтобы увидеть это на примере.
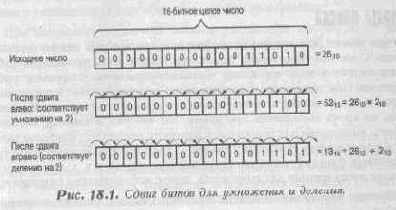
Сдвигая число влево, вы умножаете его каждый раз на 2. Проделав это четыре раза, вы умножите его на 16, пять раз — на 32. Таким путем мы можем умножить число на любую степень двух, но как насчет других'чисел, таких, например, как 26? Для выполнения этого мы разобьем умножение на группы умножений по степеням двух. Число 26 может быть представлено как 16+8+2. Таким образом, если мы умножим произвольное значение Х на 16, добавим к нему X, умноженное на 8 и, наконец, добавим X, умноженное на 2, то ответ должен быть таким же, как если бы мы умножили на 26.
Взгляните:
Y=X*26=X*16+X*8+X*2=X<<4+X<<3+X<<1
Кстати, именно так поступают ученые-ракетчики, которые прекрасно знают, что сдвиг гораздо быстрее умножения, и мы также можем выиграть кучу времени, используя эту «реактивную» технику. Увеличение скорости вычислений достигается за счет того, что сдвиг — простая бинарная операция, в то время как умножение является действием гораздо более комплексным.
В связи со сказанным стоит упомянуть еще вот о чем;
§ Во-первых, деление также может быть выполнено путем сдвига числа, но только вправо. Правда, деление сдвигом выполняется не так часто, как умножение, поскольку делитель разбить на составляющие обычно бывает значительно сложнее.
§ Во-вторых, эта техника работает только с целыми числами без плавающей запятой. Значения типа FLOAT и DOUBLE хранятся в памяти в так называемом IEEE-формате, и их сдвиг приведет к переполнению разрядной .сетки.
Теперь мы можем перейти к следующей технике оптимизации — к таблицам поиска. Что ж, поищем их...
Таблицы поиска
Таблицы поиска, как следует из их названия, служат для поиска некоторых фактов. С их помощью можно искать что угодно. Суть применения таблиц поиска состоит в том, что вместо выполнения расчетов в процессе работы программы, мы предварительно выполняем все возможные вычисления, в которых может возникнуть необходимость, и сохраняем их в гигантской таблице. Далее, во время выполнения программы, мы смотрим в таблицу, используя параметр вычисления для поиска в ней конечного результата. Наиболее классическое использование справочных таблиц — предварительное вычисление трансцендентных функций, таких как синус, косинус, тангенс и т. д., поскольку они отнимают много времени для вычисления, даже с математическим сопроцессором.
Приведу пример использования справочных таблиц. Скажем, в программе нам необходимо вычислять синус и косинус угла, который может быть любым от 0° до 360° и является целым (то есть у нас не будет вычислений для углов с десятичной частью, таких как 3.3).
Следующая программа создает справочную таблицу значений синусов и косинусов:
float sin_table[360],cos_table[360] ;
for(index=0;index<360;index++)
{
sin_table[index]=sin(index*3.14159/180);
cos_table[index]=cos (index*3.14159/180) ;
}
Этот программный фрагмент создает две таблицы, содержащих по 360 заранее вычисленных значений синусов и косинусов.
Теперь посмотрим, как использовать справочные таблицы, К примеру взглянем на это выражение:
x=cos(ang*3.14159/180)*radius;
y=sin(ang*3.14159/180)*radius;
Используя наши новые справочные таблицы, мы могли бы иметь:
x=cos_table[ang]*radius;
y=sin_table[ang]*radius;
Применение справочных таблиц может значительно увеличить быстродействие ваших игр. Единственная сложность заключается в том, что они отнимают много места. К примеру, игра Wing Commander использует справочные таблицы, которые содержат предварительно вычисленные виды кораблей для всех углов поворота. DOOM использует справочные таблицы, чтобы помочь в вычислении видимого расположения всех объектов игрового пространства.
При построении справочной таблицы учитывается все, что игрок может увидеть на экране. Необходимые для графических построений данные вычисляются перед началом игры или загружаются в готовом виде с диска. Затем, во время игры справочные таблицы получают привязку к окружающему игровому пространству и если табличные данные сообщают, что некоторую часть изображения невозможно увидеть, то графическая система устранения скрытых поверхностей удалит их.
Я сторонник идеи, что полноценная видеоигра может быть сделана только с огромным количеством справочных таблиц, и лишь небольшим программным кодом, отвечающим за осуществление игровой логики, а то и вовсе без такового. Как и в электротехнике, в видеоиграх используются конечные автоматы (с которыми мы столкнулись в тринадцатой главе, «Искусственный интеллект»). Однако вместо использования алгоритмов, моделирующих поведение объекта для следования из одного состояния в другое (как мы делали в тринадцатой главе), для управления существами можно привлечь справочные таблицы.
Этим техническим приемом в вычислительной технике пользуются для конструирования КА и мы также можем делать это в наших программах. Все что нам необходимо, это таблица, которая содержит текущее состояние и следующие состояния.
Итог: справочные таблицы великолепны. Применяйте их во всех случаях компьютерной жизни пока позволит объем памяти. Кроме того, когда вы составляете справочные таблицы, попробуйте, где это только возможно, использовать симметрию для уменьшения размера таблицы. Например, синус и косинус
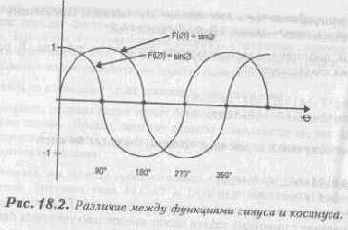
по сути являются одной и той же функцией с различием в 90о. Взгляните на рисунок 18.2. Мы видим, что синус и косинус выглядят почти одинаково. Фактически, они связаны следующими формулами:
sin (angle)=cos(angle-90) cos (angle)=sin(angle+90)
Поэтому мы могли бы создать единственную справочную таблицу для значений косинусов, а потом, когда нам понадобится вычислить синус угла, достаточно к исходной величине угла добавить 90е и использовать новый результат как индекс. Конечно, при этом нужно быть осторожным — новый угол может оказаться больше 360°. В этом случае вы должны выполнить его циклический возврат к нулю:
if(angle>360) angle=angle-360;
Для, доказательства того, что справочные таблицы могут увеличить скорость выполнения программ, я создал программку, которая использует как обычные функции sin и cos, так и справочную таблицу, хранящую заранее вычисленные значения синусов и косинусов, изображающую 100 окружностей. Программа, показанная в Листинге 18.1, начинается с заполнения таблиц. Затем она чертит 1000 окружностей, используя внутренние функции. Потом она ждет нажатия клавиши, после чего рисует 1000 окружностей, используя табличные данные. Запустив программу, вы обязательно почувствуете разницу. Также обратите внимание, что эта программа достаточно компактна и очень эффективна с точки зрения вывода графики.
Листинг 18.1. Сравнение выполнения программы с использованием справочных таблиц и встроенных функций sin и cos (LOOKNUP.C).
#include <math.h>
#include <stdio.h>
#include <graph.h>
float sin_table[360], cos_table[360];
main()
{
int index, x,y,xo,yo,radius,color,ang;
char far *screen = (char far *)0xA0000000;
// использовать библиотеку Microsoft для перехода
// в режим 320х200х256
_setvideomode(_MRES256COLOR);
// создать таблицы быстрого доступа
for (index=0; index<360; index++)
{
sin_table[index]= sin(index*3.14159/180} ;
cos_table[index]= cos(index*3.14159/180);
}
// нарисовать 1000 окружностей, используя встроенные
// функции sin и cos
for (index=0; index<1000; index++)
(
// получить случайные числа
radius = rand()%50;
xo = rand()%320;
yo = rand(}%200;
color = rand()%256;
for (ang=0; ang<3 60; ang++)
{
x = xo + cos(ang*3.14159/180) * radius;
У = yo + sin(ang*3.14159/180) * radius;
// нарисовать точку окружности
screen[(y<<6) + (y<<8) + x] = color;
}
}// все, ждать пока пользователь нажмет клавищу
printf("\nHit, a key to see circles drawn twith look up tables.");
getch();
_setvideomode(_MRES256COLOR);
// нарисовать 1000 окружностей, используя таблицы поиска
for (index=0; index<1000; index++)
{
// нарисовать случайную окружность
radius = rand()%50;
хо = randO %320;
уо = rand()%200;
color = rand()%256;
for (ang=0; ang<3 60; ang++)
{
x = хо + cos table[ang] * radius;
у = уо + sin_table[ang] * radius;
// нарисовать точку окружности
screen[(y<<6) + (y<<8) + x] = color;
} }
// подождать, пока пользователь нажмет любую клавишу
printf("\nHit any key to exit."};
getch();
_setvideomode(_DEFAULTMODE);
}
После запуска LOOKNUP.C вы должны согласиться, что справочные таблицы крайне удобны и могут здорово увеличить скорость выполнения программы.
Следующая тема будет касаться математики с фиксированной запятой.
Математика с фиксированной запятой
Математика с фиксированной запятой? Нет, это не новая точка зрения на дробные числа. Просто это немного другой путь рассмотрения компьютерной математики.
Существуют две формы математики, предназначенные для компьютера:
• Математика целых чисел;
• Математика с плавающей запятой.
Первая использует значения типов CHAR, INTEGER, LONG и т. д. Вторая оперирует числами FLOAT, DOUBLE и т. п. Разница между двумя этими видами математики заключается в том, как представлены числа в памяти и какие именно числа - целые или дробные - принимают участие в расчетах. Целые числа представлены в компьютере непосредственно в двоичной форме, без какого-либо кодирования. Как вы знаете, они могут быть как положительными, так и отрицательными, и у них отсутствует дробная часть. С другой стороны, числа с плавающей запятой должны иметь десятичные части.
Но к чему такая забота по поводу чисел? Объясняю: ПК может выполнять математические вычисления весьма быстро, но «весьма быстро» еще не значит «достаточно быстро для видеоигр». Даже с математическим сопроцессором ПК до сих пор оставляет желать лучшего в режиме реального времени при работе с трехмерной графикой. Известно, что вычисления с целыми выполняются гораздо быстрее, чем с дробными числами.
Вы можете спросить: «Почему мы обязательно должны использовать числа с плавающей запятой?» Ответ заключается в том, что по природе того типа программирования, которым мы занимаемся (трехмерная компьютерная графика), мы оказываемся перед неизбежной необходимостью достижения максимальной точности в наших вычислениях. Это заставляет нас использовать и дробные числа тоже.
Вычисления с плавающей запятой пожирают так много времени из-за способа представления чисел, с которыми они оперируют. Эти числа не являются в полном смысле двоичными, напротив, они хранятся в специальном формате IEEE, в котором характеристика (целая часть) и мантисса (экспонента) представлены в жутко свернутой форме, и прежде чем число использовать в вычислениях, его нужно еще расшифровать. Числа — это только инструмент для представления игровых объектов. Если бы вы захотели, то могли бы разработать свои собственные форматы хранения десятичных чисел.
Это та область, где в бой вступает математика с фиксированной запятой. Например, можно представить число содержащим как целую, так и десятичную часть внутри отдельного целого. Как это сделать? Притворимся, что десятичные части существуют где-то внутри целого и что двоичные цифры слева являются целой частью числа, а все, что находится справа, это десятичная часть. Рисунок 18.3 должен помочь вам представить это.
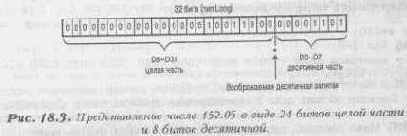
Где именно вы поместите десятичную часть, зависит от вас. Важно, чтобы позиция десятичной точки и выбор базового типа данных удовлетворяли нашим потребностям. Я предлагаю использовать тип данных LONG, который имеет 32 бита точности, а десятичную точку поместить где-нибудь посередине. Скажем, отведем для десятичной части восемь младших битов, тогда целая часть займет 24 старших разряда. Этого более чем достаточно для наших потребностей, поскольку в видеоиграх не нужна очень высокая точность. Пары знаков после запятой будет вполне достаточно. Чтобы использовать математику с фиксированной запятой, нам необходимо только разобраться, как выполнять с ней несколько операций:
§ присваивание;
§ сложение;
§ вычитание;
§ умножение;
§ деление;
§ сравнение.
Прежде чем разобраться в способах осуществления этих операций, мы все-таки должны понять как объявить число с фиксированной запятой. Взгляните, это действительно трудно:
long fix_1,fix_2,fix_3;
Что, обманул вас на секунду, да? Не правда ли, проще не придумаешь? Как я сказал ранее, мы используем тип данных LONG для чисел с фиксированной точкой и только предполагаем наличие десятичной части. И это все, что нам нужно для определения числа с фиксированной запятой.
Присваивание
Теперь поговорим о присваивании. Если мы хотим присвоить целую часть фиксированного числа, мы делаем .следующее:
int а=300;
long fix_1=0;
// в двоичном виде - 0000 0000 0000 0000 0000 0000 0000 0000
fix_1=((long)a << 8);
Сложнее обстоит дело с присваиванием дробных чисел. Для этого мы должны использовать умножение с плавающей запятой и записать число в LONG. Ниже показано, как выполнить такую операцию присваивания:
long fix_1 = (long) (23.4*256)
Мы умножаем на 256 потому, что это эквивалентно сдвигу на восемь разрядов влево (помните, я уже говорил, что нет смысла сдвигать числа с плавающей запятой).
Сложение и вычитание
Чтобы складывать или вычитать числа с фиксированной запятой, мы можем использовать обычные операторы Си. К примеру, чтобы сложить два числа и записать результат в третье, мы могли бы сделать так:
fix_3=fix_1+fix_2
Вычитание получается точно так же. Кроме того, вы можете использовать и отрицательные значения, поскольку внутреннее представление типа данных LONG учитывает знак, и это вполне применимо также и к числам с фиксированной запятой.
Умножение
Самая сложная из всех операций — это умножение. Здесь мы должны соблюдать осторожность: существует несколько нюансов, которые могут наплодить множество ошибок. Например, когда умножаются два числа с фиксированной запятой, для сохранения результата может потребоваться в два раза больше битов, нежели содержат сомножители. Другими словами, если оба сомножителя были 32-битными, не исключена возможность получить 64-битный результат. То есть мы должны следить за величиной чисел с фиксированной запятой, которые перемножаются. Как и обычно, для этого мы будем использовать оператор умножения. Однако когда умножение выполнено, мы должны сдвинуть результат на 8 позиций назад вправо. Это нужно сделать потому, что когда мы задаем число с фиксированной запятой, то искусственно перемножаем его на 256 (помните, восемь младших разрядов заняты под десятичную часть).
Поэтому мы должны сдвинуть окончательный результат назад восемь раз вправо, иначе говоря, результат должен быть разделен на 256. Если этого не сделать, то, умножая 2 на 5, мы получим 2х5х256 вместо правильного ответа равного 10. Здесь приводится способ, каким делать умножение.
fix_1=(fix_2*fix_3)>>8;
Если вы хотите вычислить сумму произведений, то нет надобности после каждого умножения сдвигать результат. Достаточно сделать это только один раз в самом конце расчетов. Рассмотрим пример:
fix_1=(fix_2*fix_3+fix_4*fix_5)>>8;
Это свойство чисел с, фиксированной запятой могло бы пригодиться, если вы захотите оптимизировать приведенный фрагмент и дальше с целью избавиться от всех сдвигов.
Деление
При выполнении деления я предлагаю вместо использования символа деления умножать на обратную величину. Как правило, это несложно сделать. Запомните, что деление — всегда более медленная операция, чем умножение, независимо от того, применяете вы числа с фиксированной или с плавающей запятой. Здесь приводится пример того, как могло бы быть выполнено деление:
fix_1=(long)(256*1/34);
fix_2=(fix_3*fix_1)>>8 ;
Прежде чем мы перейдем к следующей теме, мне бы хотелось затронуть некоторые детали, о которых прочие авторы обычно не любят говорить. Это точность и максимальное цифровое представление.
Точность
Поскольку мы договорились, что в нашем формате чисел с фиксированной запятой восемь младших разрядов будут содержать десятичную часть, то самым маленьким числом, которое можно представить, окажется значение 1/256 или примерно 0.004. Следовательно, максимальная ошибка будет получаться при умножении двух чисел. Наибольшее число, которое мы можем получить в произведении, равно 32761. Следовательно, наибольшая ошибка, которая может закрасться в расчеты, это 0.004х32761 или 131.044. Ого! Это слишком много. Однако в действительности у нас никогда не будет ошибок такой величины. Только вы не должны с одним и тем же числом выполнять больше 2-5 умножений, и сомножители не должны превышать 32761.
Как правило, в большинстве случаев ошибки не будут превышать 0.01-0.5, что вполне допустимо, поскольку 90 процентов всех расчетов направлены на определение местоположения пикселей на экране и результаты все равно округляются.
Хватит насчет точности. Перейдем к определению максимального числа, которое может быть представлено в нашей системе с фиксированной запятой.
Максимальное цифровое представшие
Поскольку у нас есть 24 бита для целой и 8 бит для десятичной части числа, вы можете подумать, что таким образом можно представить значения вплоть до 224 или 16777216. Почти, но не совсем. Так как число с фиксированной запятой может быть и положительным и отрицательным, мы располагаем числами в диапазоне от -8388608 до +8388608. Мы можем без всяких проблем складывать и вычитать числа из этого диапазона, но при умножении, должны быть исключительно осторожны, чтобы не переполнить тип LONG.
Когда я изучал математику с фиксированной запятой в первый раз и пытался алгоритмизовать ее, то допустил ошибку. Я использовал схему, похожую на нашу (то есть 24 бита для целой части и 8 бит для десятичной) и думал, что наибольшие числа, пригодные для умножения, могут быть любыми, лишь бы результат укладывался в 24 бита. Это означало бы, что можно перемножить 4096 на 4096 и получить правильный ответ. Ошибочка! Я забыл об остальных 8 битах десятичной части- Следовательно, в действительности я умножил 4096х256х4096х256, что составляет примерно 1.09х1012. Поскольку тип LONG состоит из 32-х битов, то он может представлять числа от -2147483648 до +2147483648 (которые в 1000 раз меньше полученного результата). Мораль сей басни такова, что числа с фиксированной запятой остаются принадлежащими типу LONG, и если в них записать числа, интерпретируемые как LONG, то при умножении возникнет переполнение.
Наибольший результат умножения, который может быть получен в нашей системе с фиксированной запятой равен 32761 или 181 в степени 2. Число 181 было получено исходя из следующих соображений: это число, которое, будучи умноженным на 256 и возведенным в квадрат, не должно превышать размерности типа LONG (+2147483648).
Мы используем 256, так как у нас есть восемь двоичных цифр, a 28 равно 256.
Как, ни странно, но наибольшее число, которое может быть получено в результате умножения — это 32761, а величина чисел для сложения может достигать примерно 8000000? Ну что ж... где-то мы нашли, а где-то потеряли.
Чтобы помочь вам в экспериментах с числами с фиксированной запятой и увидеть некоторые их интересные свойства, я создал небольшую библиотеку и программу main() для демонстрации их использования (Листинг 18.2). Я предлагаю вам потратить немного времени, чтобы получить действительно целостное понимание сути чисел с фиксированной запятой, поскольку это очень важно и про это мало кто знает. Никогда не надо забывать, что десятичная запятая является воображаемой!
Листинг 18.2. Функции библиотеки системы с фиксированной запятой (FIX.C).
// ВКЛЮЧАЕМЫЕ ФАЙЛЫ ///////////////////////////////
#include <math.h>
#include <stdio.h>
// определим наш новый тип чисел с фиксированной запятой
typedef long fixed;
//ФУНКЦИИ ///////////////////////////////////////////
fixed Assign_Integer(long integer)
{
return((fixed)integer << 8);
} // конец функции присваивания целочисленного значения ////////////////////////////////////////////////////////////
fixed Assign_Float(float number)
{
return((fixed)(number * 256)};
} // конец функции присваивания значения с плавающей запятой ////////////////////////////////////////////////////////////
fixed Mul_Fixed(fixed fl,fixed f2)
{
return ((fl*f2) >> 8);
} //конец функции умножения ////////////////////////////////////////////////////////////
fixed Add_Fixed(fixed fl,fixed f2)
{
return(f1+f2);
} // конец функции сложения ////////////////////////////////////////////////////////////
Print_Fixed(fixed fl)
{
printf("%ld.%ld", f1>>8, 100*(unsigned long) (f1 & 0x00ff)/256);
} // конец функции вывода числа с фиксированной запятой
// ОСНОВНАЯ ПРОГРАММА //////////////////////////////////////
main(}
{
fixed f1,f2,f3;
fl = Assign_Float(15);
f2 = Assign_Float(233.45);
f3 = Mul_Fixed(f1,f2);
printf("\nf1:");
Print_Fixed(f);
printf("\nf2:");
Print_Fixed(f2) ;
printf("\nf3:");
Print_Fixed(f3) ;
} // конец функции main
Конечно, в собственных программах вы фактически не будете использовать функции сложения и умножения. Я поместил их здесь только для того, чтобы вы могли поэкспериментировать со свойствами чисел с фиксированной запятой.
Теперь перейдем к встроенному ассемблеру.
Встроенный ассемблер
Ассемблировать или не ассемблировать: вот в чем вопрос. Почти шекспировская задача и нам ее сейчас предстоит разрешить.
Как я говорил ранее, вы должны использовать MASM и встроенный ассемблер, только если в этом действительно возникает необходимость. Ведь все равно операции, которые вы выполняете, являются машинно-зависимыми по своей природе. Вам не нужен ассемблер ни для чего, кроме создания графики и звука. Ни в коем случае не стоит использовать ассемблер для реализации игровой логики и алгоритмов. Кроме того, если ассемблер вам необходим для увеличения быстродействия, применяйте вместо MASM встроенный ассемблер. Он проще в использовании и его применение отнимает меньше времени при разработке программ. Мы обсудим несколько методов, которые увеличат скорость выполнения ваших программ во много раз.
Теперь рассмотрим некоторые из функций, которые мы написали в предыдущих главах и оптимизируем их с помощью новых технических приемов.
Оптимизация рисования пикселей
Первое, что мы должны сделать, это насколько возможно оптимизировать по быстродействию функцию рисования пикселей. Ведь на ней базируются, все остальные графические построения! Давайте возьмем функцию Plot_Pixel() из Листинга 5.4 (вы найдете ее в пятой главе «Секреты VGA-карт») и поглядим можем ли мы оптимизировать ее дальше. Листинг 18.3 содержит новую функцию.
Листинг 18.3. Функция для быстрого рисования пикселей.
void Plot_Pixel_Fast(int x,int y,unsigned char color)
(
// Функция рисует на экране точку несколько быстрее
// за счет использования сдвига вместо умножения:
// 320 * у = 256 * у + 64 * у = у << 8 + у << 6
video_buffer[((у<<8}+(у<<6) )+х]=соlоr;
}
Все. С точки зрения Си эта функция уже оптимизирована настолько, насколько возможно. Я могу вам предложить только следующее:
§ Перепишите программу на встроенном ассемблере;
§ Не передавайте параметры;
§ Возможно, создайте справочную таблицу из 64000 элементов, каждый из которых содержит адрес видеобуфера, соответствующий координатам Х и Y.
Правда, я думаю, что использование справочной таблицы на самом деле только замедлит выполнение программы. Ведь операция индексирования таблицы может отнять больше времени, чем два сдвига и сложение, необходимые для вычисления адреса. Но вот первые два пункта заслуживают внимания. Начнем с использования глобальных переменных, заменяющих передачу параметров. Например, определим такие глобальные переменные:
int plot_x, plot_у, plot_color;
Тогда нашу функцию можно переписать, как показано в Листинге 18.4
Листинг 18.4. Другая версия функции построения пикселя.
void Plot_Pixel_Global(void)
{
video_buffer[((plot_y<<8) + (plot_y<<6))+plot_x]=plot_color;
}
Это уже будет работать значительно быстрее, но нам все равно перед вызовом нужно выполнить операцию присваивания для переменных plot_x, plot_у и plot_color. Следовательно, вопрос в следующем - отнимет ли операция присваивания глобальных переменных меньше времени, чем передача параметров, создание и удаление фрейма стека вместе со ссылками на параметры? Может да, а может и нет. Все зависит от ситуации. Но цель заслуживает того, чтобы попробовать испытать и этот метод.
Теперь перепишем процедуру на ассемблере. Результат показан в Листинге 18.5
Листинг 18.5. Версия функции рисования пикселя на ассемблере.
Plot_Pixel_Asm(int x,int у,int color)
{
_asm{
les di,video_buffer // загрузить регистр es значением
// сегмента видеобуфер
mov di,y // поместить в di у-координату пикселя
shl di,6 // умножить на 64
mov bx,di // сохранить результат
shl di,2 // умножить еще на 8 (итого, на 256)
add di,bx // сложить результаты
add di,x // прибавить х-компонент
mov al,BYTE PTR color // записать цвет в регистр аl
mov es:[di],al // нарисовать пиксель
}
}
Ладно, покончим с этим. Ассемблерный вариант работает всего лишь на 2 процента быстрее, чем версия на Си. На то есть две причины:
§ Во-первых, компилятор Си проделывает неплохую работу, транслируя программу в машинные коды. Хотя, как вы знаете, мы можем сделать это вручную, используя ассемблер;
§ Во-вторых, когда вы используете встроенный ассемблер, он сохраняет все регистры и позже восстанавливает их. Единственный способ избавления от этого - написать внешние ассемблерные функции с использованием MASM. В данном случае это вполне допустимо, поскольку мы оптимизируем такую важную операцию как построение пикселя.
Наконец, я хочу показать вам последний пример оптимизации, которая позволяет ускорить вывод на экран в два раза.
Оптимизация изображаемой линии
Игры типа DOOM и Wolfenstein 3-D не используют все известные техники трехмерных графических преобразований, как это делают, например, имитаторы полетов. В них применяются совершенно гениальные методы для создания трехмерных образов. Эти методы базируются на изображении большого количества линий, проходящих в одном направлении. Обычно рисуются обычно вертикальные или горизонтальные линии и только в удаленных предметах присутствуют диагональные прямые. Следовательно, мы должны научиться максимально быстро проводить горизонтальные и вертикальные линии. Сейчас мы поговорим о горизонтальных прямых.
Как мы проходили в пятой главе «Секреты VGA-карт», для изображения горизонтальной линии лучше всего применить функцию memcpy () (см. Листинг 5.6). Начальный и конечный адреса вычисляются из Х-координат крайних точек линии. Вернувшись назад к этому методу, приходится признать, что он не совсем совершенен, поскольку memcpyO для перемещения данных использует тип BYTE. Но профессионалы в программировании игр знают, что VGA-карта работает быстрее с данными типа WORD. Следовательно, нужно попытаться исправить этот недостаток и записывать в видеобуфер WORD вместо BYTE. Сейчас я собираюсь переписать функцию изображения горизонтальных линий, учитывая это пожелание.
Это не так легко, как кажется, потому что конечной целью должна быть забота о работоспособности. Вы видите, что когда вы пишите WORD в видеобуфер, вы в сущности строите два пикселя. Вы должны быть осторожны, принимая это во внимание во время рисования линий. Скажем, мы хотели изобразить линию, тянущуюся от точки (51,100) до точки (100,100). У нас получится линия, которая выглядит чем-то похожей на рисунок 18.4.
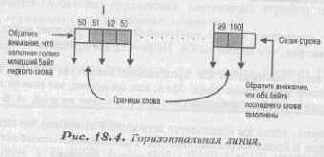
Завершим анализ изображения этой линии тем, что каждая конечная точка в действительности занимает один байт, а не два. Следовательно, мы должны написать программу, которая может управлять состоянием, когда конечные точки BYTE или WORD граничат. Программа из Листинга 18.6 делает это.
Листинг 18.6. Программа, изображающая горизонтальную линию и использующая для этого тип WORD (HLINEF.C).
H_Line_Fast(int xl,int x2,int у,unsigned int color)
{
unsigned int first_word, middle_word, last_word,line_offset,
index ;
// тестируем 1 бит начальной х-координаты
if ( (x1 & 0х0001))
{
first_word = (color << 8);
}
else
{
// заменить цвет в обоих байтах
first_word = ( (color<<8) | color) ;
}
// тестируем первый бит в х2
if( (х2 & 0х0001) )
{
last_word = ((color<<8) | color);
)
else
{
// поместить цвет только в старший байт
last_word = color;
}
// теперь мы можем рисовать горизонтальную линию,
// выводя сразу по два пикселя
line_offset = ( (у<<7) + (у<<5) ); // у*160, поскольку в линии 160 слов
// вычислить цвет в середине
middle_word = ((color<<8) | color);
// левая граница
video_buffer_w[line_offset + (x1>>1)]= first_word;
// середина линии
for (index=(x1>>1)+l, index<(x2>>l); index++)
video_buffer_w[line_offset+index] = middle_word;
// правая граница video_buffer_w[line_offset+(х2>>1)] = last_word;
}
В начале работы функция проверяет, находятся ли конечные точки на границе байта (BYTE)? Основываясь на результатах проверки, функция создает два слова (WORD): одно будет началом линии, а другое ~ концом. В зависимости от результатов начального теста эти два слова содержат либо один, либо два байта, представляющих цвет. Затем функция изображает линию. Это выполняется следующим образом:
§ Пишется первый WORD, соответствующий левой границе;
§ Создается цикл FOR, который предназначен для записи в WORD середины линии;
§ Пишется WORD, соответствующий правой границе линии.
Хотя эта функция почти в два раза длиннее, чем первоначальная Н_Line, она почти в два раза быстрее.
(Существуют, правда, небольшие накладные расходы при вычислении границы). Чтобы сделать ее еще быстрее, я мог бы переписать часть, которая изображает середину на встроенном ассемблере, но я думаю, что вы и сами сделаете это в качестве легкого упражнения.
ИТОГ
Мы узнали множество полезных вещей, и даже если вы никогда не начнете писать игры, определенно станете более умелым программистом, поскольку приобрели новые навыки. У вас появилось несколько мощных методов оптимизации. Только не думайте, что лучше этих методов не бывает или что предложенные способы оптимизации годятся на все случаи жизни.
Наше длинное путешествие в мир оптимизации подошло к концу, и я хочу закончить его приглашением в следующую, девятнадцатую главу, где мы, наконец, на примере игры Warlock применим все, чему уже научились.Итак, до следующей главы.